Collecter la donnée
Après avoir défini la problématique, l'étape suivante est donc de récupérer le code source sur lequel travailler. Un énorme avantage dans ce domaine, c'est de disposer d'une très grande source de données, librement accessibles et téléchargeables: Github. Le codelab propose de se concentrer sur une organisation en particulier, intéressante pour la variété des sujets abordés et la quantité d'informations disponibles : Apache.
Github propose une API publique qui peut être requêtée afin de récupérer la liste des organisations et la liste des dépôts de code associés. C'est un bon point de départ, néanmoins la récupération des données pose quelques problèmes de performance (temps de téléchargement) et de stockage (taille des fichiers sur le disque dur). Pour aller plus vite, la recherche est donc limitée aux dépôts populaires, c'est à dire avec un nombre minimum de favoris et en évitant les dépôts les plus gros, certains dépôts d'Apache étant vraiment volumineux.
Ces restrictions prises en compte, il s'agit maintenant :
- de télécharger le code en tant que tel (avec
git clone/git checkout) - de paralléliser ces téléchargements pour gagner du temps
- de filtrer et de nettoyer les dépôts
L'étape de filtrage est nécessaire car les dépôts contiennent en général, en plus du code source, des fichiers de configuration, des librairies tierces... qui sont peu intéressantes pour l'analyse. Il s'agit de supprimer, par exemple:
- les fichiers de configuration (protobuf, settings, ...)
- les répertoires
vendors - etc.
Une fois le code récupéré localement, on peut parcourir l'arborescence des répertoires, de lire les fichiers un par un et de consulter l'historique git en ligne de commande. C'est en réalité plutôt fastidieux et une approche plus pragmatique est proposée, utilisant un outil open-source développé par source{d}: Gitbase.
Cet outil permet de charger automatiquement le contenu des dépôts, de les exposer comme une base de données et d'en simplifier l'exporation via des requêtes SQL. Voici par exemple un apercu des tables du modèle Gitbase utilisées pour le codelab :
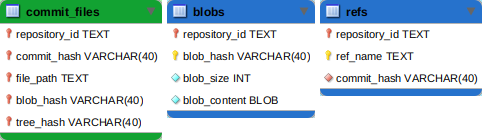
Gitbase permet ainsi de travailler plus rapidement et plus efficacement qu'en allant parcourir manuellement tous les fichiers de tous les dépôts. On dispose grâce à Gitbase d'une structure organisée permettant d'explorer l'arborescence en lançant des recherches dans une base de données. Il s'agit maintenant d'analyser le contenu des fichiers, le code en lui-même.
Analyser la donnée
Le code source étant présenté sous forme de fichiers texte, il est possible de le traiter comme un flux des caractères qu'on peut parser pour extraire l'information, par exemple avec des expressions régulières ou des machines à état. C'est un travail assez long et surtout, il faut décliner les expressions régulières pour chacun des langages de programmation potentiellement recontrés dans les dépôts (Java, Python, JS, etc.)
L'outil Babelfish facilite la mise en oeuvre de cette étape. Il permet de construire un arbre syntaxique (ou AST) qui est une représentation logique de la structure d'un fichier source. Cet arbre syntaxique peut ensuite être parcouru avec des requêtes XPath, ce qui permet d'extraire directement les infomations pertinentes (par exemple, les noms de variables, les méthodes, etc.).

De plus Babelfish supporte nativement une quinzaine de langages de programmation parmi les plus populaires, c'est une tâche de moins à réaliser. Enfin, l'équipe de Gitbase a mis en place une inter-opérabilité avec Babelfish, permettant de lancer les recherches XPath directement sur le contenu indexé par la base de données.
On dispose ainsi grâce à Babelfish d'une donnée structurée permettant de parcourir, via des requêtes XPath, le contenu syntaxique de l'ensemble des fichiers préalablement récupérés.
Dans un dernier article, je décrirai la mise en oeuvre du modèle d'apprentissage et la manière dont on peut l'évaluer et le présenter.